Robots txt как запретить все. Чем меньше страниц индексируется тем больше трафика

Robots.txt для wordpress один из главных инструментов настройки индексации. Ранее мы говорили об ускорении и улучшении процесса индексации статей. Причем рассматривали этот вопрос так, как будто поисковый робот ничего не знает и не умеет. А мы ему должны подсказать. Для этого мы использовали карту сайта файл .
Возможно вы еще не догадывается, как поисковый робот индексирует ваш сайт? По умолчанию индексировать ему разрешено всё. Но делает он это не сразу. Робот, получив сигнал о том, что нужно посетить сайт, ставит его в очередь. Поэтому индексация происходит не мгновенно по нашему требованию, а через какое-то время. Как только очередь доходит до вашего сайта, этот робот-паук тут как тут. Первым делом он ищет файл robots.txt.
Если robots.txt найден, то прочитывает все директивы, а в конце видит адрес файла . Дальше робот, в соответствии с картой сайта, обходит все материалы предоставленные для индексации. Делает он это в пределах какого-то ограниченного промежутка времени. Именно поэтому, если вы создали сайт на несколько тысяч страниц и выложили его целиком, то робот просто не успеет обойти все страницы за один заход. И в индекс попадут только те, которые он успел просмотреть. А ходит робот по всему сайту и тратит на это свое время. И не факт что в первую очередь он будет просматривать именно те странички, которые вы так ждёте в результатах поиска. 
Если робот файл robots.txt не находит, то считает, что индексировать разрешено всё. И начинает шарить по всем закаулкам. Сделав полную копию всего, что ему удалось найти, он покидает ваш сайт, до следующего раза. Как вы понимаете, после такого обшаривания в базу индекса поисковика попадает всё, что надо и всё, что не надо. То что надо вы знаете - это ваши статьи, страницы, картинки, ролики и т.д. А вот чего индексировать не надо?
Для WordPress это оказывается очень важный вопрос. Ответ на него затрагивает и ускорение индексации содержимого вашего сайта, и его безопасность. Дело в том, что всю служебную информацию индексировать не надо. А файлы WordPress вообще желательно спрятать от чужих глаз. Это уменьшит вероятность взлома вашего сайта.
WordPress создаёт очень много копий ваших статей с разными адресами, но одним и тем же содержанием. Выглядит это так:
//название_сайта/название_статьи,
//название_сайта/название_рубрики/название_статьи,
//название_сайта/название_рубрики/название_подрубрики/название_статьи,
//название_сайта/название_тега/название_статьи,
//название_сайта/дата_создания_архива/название_статьи
С тегами и архивами вообще караул. К скольким тегам привязана статья, столько копий и создаётся. При редактировании статьи, сколько архивов в разные даты будет создано, столько и новых адресов с практически похожим содержанием появится. А есть ещё копии статей с адресами для каждого комментария. Это вообще просто ужас.
Огромное количество дублей поисковые системы оценивают как плохой сайт. Если все эти копии проиндексировать и предоставить в поиске то вес главной статьи размажется на все копии, что очень плохо. И не факт, что будет показана в результате поиска именно статья с главным адресом. Следовательно надо запретить индексирование всех копий.
WordPress оформляет картинки как отдельные статьи без текста. В таком виде без текста и описания они как статьи выглядят абсолютно некорректно. Следовательно нужно принять меры чтобы эти адреса не попали в индекс поисковиков.
Почему же не надо всё это индексировать?
Пять причин для запрета индексации!
- Полное индексирование создаёт лишнюю нагрузку на ваш сервер.
- Отнимает драгоценное время самого робота.
- Пожалуй это самое главное, некорректная информация может быть неправильно интерпретирована поисковыми системами. Это приведет к неправильному ранжированию статей и страниц, а в последствии и к некорректной выдаче в результатах поиска.
- Папки с шаблонами и плагинами содержат огромное количество ссылок на сайты создателей и рекламодателей. Это очень плохо для молодого сайта, когда на ваш сайт ссылок из вне еще нет или очень мало.
- Индексируя все копии ваших статей в архивах и комментариях, у поисковика складывается плохое мнение о вашем сайте. Много дублей. Много исходящих ссылок Поисковая машина будет понижать ваш сайт в результатах поиска в плоть до фильтра. А картинки, оформленные в виде отдельной статьи с названием и без текста, приводят робота просто в ужас. Если их очень много, то сайт может загреметь под фильтр АГС Яндекса. Мой сайт там был. Проверено!
Теперь после всего сказанного возникает резонный вопрос: "А можно ли как то запретить индексировать то что не надо?". Оказывается можно. Хотя бы не в приказном порядке, а в рекомендательном. Ситуация не полного запрета индексации некоторых объектов возникает из-за файла sitemap.xml, который обрабатывается после robots.txt. Получается так: robots.txt запрещает, а sitemap.xml разрешает. И всё же решить эту задачу мы можем. Как это сделать правильно сейчас и рассмотрим. 
Файл robots.txt для wordpress по умолчанию динамический и реально в wordpress не существует. А генерируется только в тот момент, когда его кто-то запрашивает, будь это робот или просто посетитель. То есть если через FTP соединение вы зайдете на сайт, то в корневой папке файла robots.txt для wordpressвы там просто не найдете. А если в браузере укажите его конкретный адрес http://название_вашего_сайта/robots.txt, то на экране получите его содержимое, как будто файл существует. Содержимое этого сгенерированного файла robots.txt для wordpress будет такое:
В правилах составления файла robots.txt по умолчанию разрешено индексировать всё. Директива User-agent: * указывает на то, что все последующие команды относятся ко всем поисковым агентам (*). Но далее ничего не ограничивается. И как вы понимаете этого не достаточно. Мы с вами уже обсудили папок и записей, имеющих ограниченный доступ, достаточно много.
Чтобы можно было внести изменения в файл robots.txt и они там сохранились, его нужно создать в статичном постоянном виде.
Как создать robots.txt для wordpress
В любом текстовом редакторе (только ни в коем случае не используйте MS Word и ему подобные с элементами автоматического форматирования текста) создайте текстовый файл с примерным содержимым приведенным ниже и отправьте его в корневую папку вашего сайта. Изменения можно делать в зависимости от необходимости.
Только надо учитывать особенности составления файла:
В начале строк цифр, как здесь в статье, быть не должно. Цифры здесь указаны для удобства рассмотрения содержимого файла. В конце каждой строки не должно быть ни каких лишних знаков включая пробелы или табуляторы. Между блоками должна быть пустая строка без каких либо знаков включая пробелы. Всего один пробел может принести вам огромный вред - БУДЬТЕ ВНИМАТЕЛЬНЫ .
Как проверить robots.txt для wordpress
Проверить robots.txt на наличие лишних пробелов можно следующим образом. В текстовом редакторе выделить весь текст, нажав кнопки Ctrl+A. Если пробелов в конце строк и в пустых строках нет, вы это заметите. А если есть выделенная пустота, то вам надо убрать пробелы и всё будет ОК.
Проверить правильно ли работают прописанные правила можно по следующим ссылкам:
- Анализ robots.txt в Яндекс Вебмастере
- Анализ robots.txt в Google Search console .
- Сервис для создания файла robots.txt: http://pr-cy.ru/robots/
- Сервис для создания и проверки robots.txt: https://seolib.ru/tools/generate/robots/
- Документация от Яндекса .
- Документация от google (англ.)
Есть ещё один способ проверить файл robots.txt для сайта wordpress, это загрузить его содержимое в вебмастер яндекса или указать адрес его расположения. Если есть какие-либо ошибки вы тут же узнаете.
Правильный robots.txt для wordpress
Теперь давайте перейдем непосредственно к содержимому файла robots.txt для сайта wordpress. Какие директивы в нем должны присутствовать обязательно. Примерное содержание файла robots.txt для wordpress, учитывая его особенности приведено ниже:
User-agent: * Disallow: /wp-login.php Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/themes Disallow: */*comments Disallow: */*category Disallow: */*tag Disallow: */trackback Disallow: */*feed Disallow: /*?* Disallow: /?s= Allow: /wp-admin/admin-ajax.php Allow: /wp-content/uploads/ Allow: /*?replytocom User-agent: Yandex Disallow: /wp-login.php Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/themes Disallow: */comments Disallow: */*category Disallow: */*tag Disallow: */trackback Disallow: */*feed Disallow: /*?* Disallow: /*?s= Allow: /wp-admin/admin-ajax.php Allow: /wp-content/uploads/ Allow: /*?replytocom Crawl-delay: 2,0 Host: site.ru Sitemap: http://site.ru/sitemap.xml
Директивы файла robots.txt для wordpress
Теперь давайте рассмотрим поподробнее:
1 – 16 строки блок настроек для всех роботов
User-agent: - Это обязательная директива, определяющая поискового агента. Звездочка говорит, что директива для роботов всех поисковых систем. Если блок предназначен для конкретного робота, то необходимо указать его имя, например Yandex, как в 18 строке.
По умолчанию для индексирования разрешено всё. Это равнозначно директиве Allow: /.
Поэтому для запрета индексирования конкретных папок или файлов используется специальная директива Disallow: .
В нашем примере с помощью названий папок и масок названий файлов, сделан запрет на все служебные папки вордпресса, такие как admin, themes, plugins, comments, category, tag... Если указать директиву в таком виде Disallow: /, то будет дан запрет индексирования всего сайта.
Allow: - как я уже говорил директива разрешающая индексирование папок или файлов. Её нужно использовать когда в глубине запрещённых папок есть файлы которые всё же надо проиндексировать.
В моём примере строка 3 Disallow: /wp-admin - запрещает индексирование папки /wp-admin, а 14 строка Allow: /wp-admin/admin-ajax.php - разрешает индексирование файла /admin-ajax.php расположенного в запрещенной к индексированию папке /wp-admin/.
17 - Пустая строка (просто нажатие кнопки Enter без пробелов)
18 - 33 блок настроек конкретно для агента Яндекса (User-agent: Yandex). Как вы заметили этот блок полностью повторяет все команды предыдущего блока. И возникает вопрос: "А на фига такая заморочка?". Так вот это всё сделано всего лишь из-за нескольких директив которые рассмотрим дальше.
34 - Crawl-delay - Необязательная директива только для Яндекса. Используется когда сервер сильно нагружен и не успевает отрабатывать запросы робота. Она позволяет задать поисковому роботу минимальную задержку (в секундах и десятых долях секунды) между окончанием загрузки одной страницы и началом загрузки следующей. Максимальное допустимое значение 2,0 секунды. Добавляется непосредственно после директив Disallow и Allow.
35 - Пустая строка
36 - Host: site.ru - доменное имя вашего сайта (ОБЯЗАТЕЛЬНАЯ директива для блока Яндекса). Если наш сайт использует протокол HTTPS, то адрес надо указывать полностью как показано ниже:
Host: https://site.ru
37 - Пустая строка (просто нажатие кнопки Enter без пробелов) обязательно должна присутствовать.
38 - Sitemap: http://site.ru/sitemap.xml - адрес расположения файла (файлов) карты сайта sitemap.xml (ОБЯЗАТЕЛЬНАЯ директива), располагается в конце файла после пустой строки и относится ко всем блокам.
Маски к директивам файла robots.txt для wordpress
Теперь немного как создавать маски:
- Disallow: /wp-register.php - Запрещает индексировать файл wp-register.php, расположенный в корневой папке.
- Disallow: /wp-admin - запрещает индексировать содержимое папки wp-admin, расположенной в корневой папке.
- Disallow: /trackback - запрещает индексировать уведомления.
- Disallow: /wp-content/plugins - запрещает индексировать содержимое папки plugins, расположенной в подпапке (папке второго уровня) wp-content.
- Disallow: /feed - запрещает индексировать канал feed т.е. закрывает RSS канал сайта.
- * - означает любая последовательность символов, поэтому может заменять как один символ, так и часть названия или полностью название файла или папки. Отсутствие конкретного названия в конце равносильно написанию *.
- Disallow: */*comments - запрещает индексировать содержимое папок и файлов в названии которых присутствует comments и расположенных в любых папках. В данном случае запрещает индексировать комментарии.
- Disallow: *?s= - запрещает индексировать страницы поиска
Приведенные выше строки вполне можно использовать в качестве рабочего файла robots.txt для wordpress. Только в 36, 38 строках необходимо вписать адрес вашего сайта и ОБЯЗАТЕЛЬНО УБРАТЬ номера строк. И у вас получится рабочий файл robots.txt для wordpress, адаптированный под любую поисковую систему.
Единственная особенность - размер рабочего файла robots.txt для сайта wordpress не должен превышать 32 кБ дискового пространства.
Если вас абсолютно не интересует Яндекс, то строки 18-35 вам не понадобятся вообще. На этом пожалуй всё. Надеюсь что статья оказалась полезной. Если есть вопросы пишите в комментариях.
Технические аспекты созданного сайта играют не менее важную роль для продвижения сайта в поисковых системах, чем его наполнение. Одним из наиболее важных технических аспектов является индексирование сайта, т. е. определение областей сайта (файлов и директорий), которые могут или не могут быть проиндексированы роботами поисковых систем. Для этих целей используется robots.txt – это специальный файл, который содержит команды для роботов поисковиков. Правильный файл robots.txt для Яндекса и Google поможет избежать многих неприятных последствий, связанных с индексацией сайта.
2. Понятие файла robots.txt и требования, предъявляемые к нему
Файл /robots.txt предназначен для указания всем поисковым роботам (spiders) индексировать информационные сервера так, как определено в этом файле, т.е. только те директории и файлы сервера, которые не описаны в /robots.txt. Этот файл должен содержать 0 или более записей, которые связаны с тем или иным роботом (что определяется значением поля agent_id) и указывают для каждого робота или для всех сразу, что именно им не надо индексировать.
Синтаксис файла позволяет задавать запретные области индексирования, как для всех, так и для определенных, роботов.
К файлу robots.txt предъявляются специальные требования, не выполнение которых может привести к неправильному считыванию роботом поисковой системы или вообще к недееспособности данного файла.
Основные требования:
- все буквы в названии файла должны быть прописными, т. е. должны иметь нижний регистр:
- robots.txt – правильно,
- Robots.txt или ROBOTS.TXT – неправильно;
- файл robots.txt должен создаваться в текстовом формате Unix. При копировании данного файла на сайт ftp-клиент должен быть настроен на текстовый режим обмена файлами;
- файл robots.txt должен быть размещен в корневом каталоге сайта.
3. Содержимое файла robots.txt
Файл robots.txt включает в себя две записи: «User-agent» и «Disallow». Названия данных записей не чувствительны к регистру букв.
Некоторые поисковые системы поддерживают еще и дополнительные записи. Так, например, поисковая система «Yandex» использует запись «Host» для определения основного зеркала сайта (основное зеркало сайта – это сайт, находящийся в индексе поисковых систем).
Каждая запись имеет свое предназначение и может встречаться несколько раз, в зависимости от количества закрываемых от индексации страниц или (и) директорий и количества роботов, к которым Вы обращаетесь.
Предполагается следующий формат строк файла robots.txt:
имя_записи [необязательные
пробелы]: [необязательные
пробелы]значение [необязательные пробелы]
Чтобы файл robots.txt считался верным, необходимо, чтобы, как минимум, одна директива «Disallow» присутствовала после каждой записи «User-agent».
Полностью пустой файл robots.txt эквивалентен его отсутствию, что предполагает разрешение на индексирование всего сайта.
Запись «User-agent»
Запись «User-agent» должна содержать название поискового робота. В данной записи можно указать каждому конкретному роботу, какие страницы сайта индексировать, а какие нет.
Пример записи «User-agent», где обращение происходит ко всем поисковым системам без исключений и используется символ «*»:
Пример записи «User-agent», где обращение происходит только к роботу поисковой системы Rambler:
User-agent: StackRambler
Робот каждой поисковой системы имеет свое название. Существует два основных способа узнать его (название):
на сайтах многих поисковых систем присутствует специализированный§ раздел «помощь веб-мастеру», в котором часто указывается название поискового робота;
при просмотре логов веб-сервера, а именно при просмотре обращений к§ файлу robots.txt, можно увидеть множество имен, в которых присутствуют названия поисковых систем или их часть. Поэтому Вам остается лишь выбрать нужное имя и вписать его в файл robots.txt.
Запись «Disallow»
Запись «Disallow» должна содержать предписания, которые указывают поисковому роботу из записи «User-agent», какие файлы или (и) каталоги индексировать запрещено.
Рассмотрим различные примеры записи «Disallow».
Пример записи в robots.txt (разрешить все для индексации):
Disallow:
Пример (сайт полностью запрещен к . Для этого используется символ «/»):Disallow: /
Пример (для индексирования запрещен файл «page.htm», находящийся в корневом каталоге и файл «page2.htm», располагающийся в директории «dir»):
Disallow: /page.htm
Disallow: /dir/page2.htm
Пример (для индексирования запрещены директории «cgi-bin» и «forum» и, следовательно, все содержимое данной директории):
Disallow: /cgi-bin/
Disallow: /forum/
Возможно закрытие от индексирования ряда документов и (или) директорий, начинающихся с одних и тех же символов, используя только одну запись «Disallow». Для этого необходимо прописать начальные одинаковые символы без закрывающей наклонной черты.
Пример (для индексирования запрещены директория «dir», а так же все файлы и директории, начинающиеся буквами «dir», т. е. файлы: «dir.htm», «direct.htm», директории: «dir», «directory1», «directory2» и т. д.):
Запись «Allow»
Опция «Allow» используется для обозначения исключений из неиндексируемых директорий и страниц, которые заданы записью «Disallow».
Например, есть запись следующего вида:
Disallow: /forum/
Но при этом нужно, чтобы в директории /forum/ индексировалась страница page1. Тогда в файле robots.txt потребуются следующие строки:
Disallow: /forum/
Allow: /forum/page1
Запись «Sitemap»
Эта запись указывает на расположение карты сайта в формате xml, которая используется поисковыми роботами. Эта запись указывает путь к данному файлу.
Sitemap: http://site.ru/sitemap.xml
Запись «Host»
Запись «host» используется поисковой системой «Yandex». Она необходима для определения основного зеркала сайта, т. е. если сайт имеет зеркала (зеркало – это частичная или полная копия сайта. Наличие дубликатов ресурса бывает необходимо владельцам высокопосещаемых сайтов для повышения надежности и доступности их сервиса), то с помощью директивы «Host» можно выбрать то имя, под которым Вы хотите быть проиндексированы. В противном случае «Yandex» выберет главное зеркало самостоятельно, а остальные имена будут запрещены к индексации.
В целях совместимости с поисковыми роботами, которые при обработке файла robots.txt не воспринимают директиву Host, необходимо добавлять запись «Host» непосредственно после записей Disallow.
Пример: www.site.ru – основное зеркало:
Host: www.site.ru
Запись «Crawl-delay»
Эту запись воспринимает Яндекс. Она является командой для робота делать промежутки заданного времени (в секундах) между индексацией страниц. Иногда это бывает нужно для защиты сайта от перегрузок.
Так, запись следующего вида обозначает, что роботу Яндекса нужно переходить с одной страницы на другую не раньше чем через 3 секунды:
Комментарии
Любая строка в robots.txt, начинающаяся с символа «#», считается комментарием. Разрешено использовать комментарии в конце строк с директивами, но некоторые роботы могут неправильно распознать данную строку.
Пример (комментарий находится на одной строке вместе с директивой):
Disallow: /cgi-bin/ #комментарий
Желательно размещать комментарий на отдельной строке. Пробел в начале строки разрешается, но не рекомендуется.
4. Примеры файлов robots.txt
Пример (комментарий находится на отдельной строке):
Disallow: /cgi-bin/#комментарий
Пример файла robots.txt, разрешающего всем роботам индексирование всего сайта:
Host: www.site.ru
Пример файла robots.txt, запрещающего всем роботам индексирование сайта:
Host: www.site.ru
Пример файла robots.txt, запрещающего всем роботам индексирование директории «abc», а так же всех директорий и файлов, начинающихся с символов «abc».
Host: www.site.ru
Пример файла robots.txt, запрещающего индексирование страницы «page.htm», находящейся в корневом каталоге сайта, поисковым роботом «googlebot»:
User-agent: googlebot
Disallow: /page.htm
Host: www.site.ru
Пример файла robots.txt, запрещающего индексирование:
– роботу «googlebot» – страницы «page1.htm», находящейся в директории «directory»;
– роботу «Yandex» – все директории и страницы, начинающиеся символами «dir» (/dir/, /direct/, dir.htm, direction.htm, и т. д.) и находящиеся в корневом каталоге сайта.
User-agent: googlebot
Disallow: /directory/page1.htm
User-agent: Yandex
5. Ошибки, связанные с файлом robots.txt
Одна из самых распространенных ошибок – перевернутый синтаксис.
Неправильно:
Disallow: Yandex
Правильно:
User-agent: Yandex
Неправильно:
Disallow: /dir/ /cgi-bin/ /forum/
Правильно:
Disallow: /cgi-bin/
Disallow: /forum/
Если при обработке ошибки 404 (документ не найден), веб-сервер выдает специальную страницу, и при этом файл robots.txt отсутствует, то возможна ситуация, когда поисковому роботу при запросе файла robots.txt выдается та самая специальная страница, никак не являющаяся файлом управления индексирования.
Ошибка, связанная с неправильным использованием регистра в файле robots.txt. Например, если необходимо закрыть директорию «cgi-bin», то в записе «Disallow» нельзя писать название директории в верхнем регистре «cgi-bin».
Неправильно:
Disallow: /CGI-BIN/
Правильно:
Disallow: /cgi-bin/
Ошибка, связанная с отсутствием открывающей наклонной черты при закрытии директории от индексирования.
Неправильно:
Disallow: page.HTML
Правильно:
Disallow: /page.HTML
Чтобы избежать наиболее распространенных ошибок, файл robots.txt можно проверить средствами Яндекс.Вебмастера или Инструментами для вебмастеров Google. Проверка осуществляется после загрузки файла.
6. Заключение
Таким образом, наличие файла robots.txt, а так же его составление, может повлиять на продвижение сайта в поисковых системах. Не зная синтаксиса файла robots.txt, можно запретить к индексированию возможные продвигаемые страницы, а так же весь сайт. И, наоборот, грамотное составление данного файла может очень помочь в продвижении ресурса, например, можно закрыть от индексирования документы, которые мешают продвижению нужных страниц.
Одним из этапов оптимизации сайта для поисковиков является составление файла robots.txt. С помощью данного файла можно запрещать некоторым или всем поисковым роботам индексировать ваш сайт или его определенные части, не предназначенные для индексации. В частности можно запретить индескирование дублирующегося контента такого как версии страниц для печати.
Поисковые роботы перед началом индексации всегда обращаются к файлу robots.txt в корневом каталоге вашего сайта, например, http://site.ru/robots.txt, чтобы знать какие разделы сайта роботу индексировать запрещено. Но даже если вы не собираетесь ничего запрещать, то данный файл все равно рекомендуется создать.
Как видно по расширению robots.txt – это текстовый файл. Для создания или редактирования данного файла лучше использовать самые простые текстовые редакторы наподобие Блокнот (Notepad). robots.txt должен быть размещен в корневом каталоге сайта и имеет собственный формат, который мы рассмотрим ниже.
Формат файла robots.txt
Файл robots.txt должен состоять как минимум из двух обязательных записей. Первой идет директива User-agent указывающая, какой поисковый робот должен следовать идущим дальше инструкциям. Значением может быть имя робота (googlebot, Yandex, StackRambler) или символ * в случае если вы обращаетесь сразу ко всем роботам. Например:
User-agent: googlebotНазвание робота вы можете найти на сайте соответствующего поисковика. Дальше должна идти одна или несколько директив Disallow. Эти директивы сообщают роботу, какие файлы и папки индексировать запрещено. Например, следующие строки запрещают роботам индексировать файл feedback.php и каталог cgi-bin:
Disallow: /feedback.php Disallow: /cgi-bin/Также можно использовать только начальные символы файлов или папок. Строка Disallow: /forum запрещает индексирование всех файлов и папок в корне сайта, имя которых начинается на forum, например, файл http://site.ru/forum.php и папку http://site.ru/forum/ со всем ее содержимым. Если Disallow будет пустым, то это значит, что робот может индексировать все страницы. Если значением Disallow будет символ /, то это значит что весь сайт индексировать запрещено.
Для каждого поля User-agent должно присутствовать хотя бы одно поле Disallow. То-есть, если вы не собираетесь ничего запрещать для индексации, то файл robots.txt должен содержать следующие записи:
User-agent: * Disallow:Дополнительные директивы
Кроме регулярных выражений Яндекс и Google разрешают использование директивы Allow, которая является противоположностью Disallow, то-есть указывает какие страницы можно индексировать. В следующем примере Яндексу запрещено индексировать все, кроме адресов страниц начинающихся с /articles:
User-agent: Yandex Allow: /articles Disallow: /В данном примере директиву Allow нужно прописывать перед Disallow, иначе Яндекс поймет это как полный запрет индексации сайта. Пустая директива Allow также полностью запрещает индексирование сайта:
User-agent: Yandex Allow:равнозначно
User-agent: Yandex Disallow: /Нестандартные директивы нужно указывать только для тех поисковиков, которые их поддерживают. В противном случае робот не понимающий данную запись может неправильно обработать ее или весь файл robots.txt. Более подробно о дополнительных директивах и вообще о понимании команд файла robots.txt отдельным роботом можно узнать на сайте соответствующей поисковой системы.
Регулярные выражения в robots.txt
Большинство поисковых систем учитывают только явно указанные имена файлов и папок, но есть и более продвинутые поисковики. Робот Google и робот Яндекса поддерживают использование простых регулярных выражений в robots.txt, что значительно уменьшает количество работы для вебмастеров. Например, следующие команды запрещают роботу Google индексировать все файлы с расширением.pdf:
User-agent: googlebot Disallow: *.pdf$В приведенном примере символ * – это любая последовательность символов, а $ указывает на окончание ссылки.
User-agent: Yandex Allow: /articles/*.html$ Disallow: /Приведенные выше директивы разрешают Яндексу индексировать только находящиеся в папке /articles/ файлы с расширением ".html". Все остальное запрещено для индексации.
Карта сайта
В файле robots.txt можно указывать расположение XML-карты сайта:
User-agent: googlebot Disallow: Sitemap: http://site.ru/sitemap.xmlЕсли у вас очень большое количество страниц на сайте и вам пришлось разбить карту сайта на части, то в файле robots.txt нужно указывать все части карты:
User-agent: Yandex Disallow: Sitemap: http://mysite.ru/my_sitemaps1.xml Sitemap: http://mysite.ru/my_sitemaps2.xmlЗеркала сайта
Как вы знаете обычно один и тот же сайт может быть доступен по двум адресам: как с www, так и без него. Для поискового робота site.ru и www.site.ru это разные сайты, но с одинаковым содержимым. Они называются зеркалами.
Из-за того что на страницы сайта есть ссылки как с www так и без, то вес страниц может разделиться между www.site.ru и site.ru. Чтобы этого не происходило поисковику нужно указать главное зеркало сайта. В результате "склеивания" весь вес будет принадлежать одному главному зеркалу и сайт сможет занять более высокую позицию в поисковой выдаче.
Указать основное зеркало для Яндекса можно прямо в файле robots.txt с помощью директивы Host:
User-agent: Yandex Disallow: /feedback.php Disallow: /cgi-bin/ Host: www.site.ruПосле склейки зеркалу www.site.ru будет принадлежать весь вес и он будет занимать более высокую позицию в поисковой выдаче. А site.ru поисковик вообще не будет индексировать.
Для остальных поисковиков выбором главного зеркала является серверный постоянный редирект (код 301) с дополнительных зеркал на основное. Делается это с помощью файла.htaccess и модуля mod_rewrite. Для этого ложим в корень сайта файл.htaccess и пишем туда следующее:
RewriteEngine On Options +FollowSymlinks RewriteBase / RewriteCond %{HTTP_HOST} ^site.ru$ RewriteRule ^(.*)$ http://www.site.ru/$1В результате все запросы с site.ru будут идти на www.site.ru, то-есть site.ru/page1.php будет перенаправляться на www.site.ru/page1.php.
Метод с редиректом будет работать для всех поисковых систем и браузеров, но все же рекомендуется добавлять для Яндекса директиву Host в файл robots.txt.
Комментарии в robots.txt
В файл robots.txt также можно добавлять комментарии – они начинаются с символа # и заканчиваются переводом строки. Комментарии желательно писать в отдельной строке, а лучше вообще их не использовать.
Пример использования комментариев:
User-agent: StackRambler Disallow: /garbage/ # ничего полезного в этой папке нет Disallow: /doc.xhtml # и на этой странице тоже # и все комментарии в этом файле также бесполезныПримеры файлов robots.txt
1. Разрешаем всем роботам индексировать все документы сайта:
User-agent: * Disallow:User-agent: * Disallow: /
3. Запрещаем роботу поисковика Google индексировать файл feedback.php и содержимое каталога cgi-bin:
User-agent: googlebot Disallow: /cgi-bin/ Disallow: /feedback.php4. Разрешаем всем роботам индексировать весь сайт, а роботу поисковика Яндекс запрещаем индексировать файл feedback.php и содержимое каталога cgi-bin:
User-agent: Yandex Disallow: /cgi-bin/ Disallow: /feedback.php Host: www.site.ru User-agent: * Disallow:5. Разрешаем всем роботам индексировать весь сайт, а роботу Яндекса разрешаем индексировать только предназначенную для него часть сайта:
User-agent: Yandex Allow: /yandex Disallow: / Host: www.site.ru User-agent: * Disallow:Пустые строки разделяют ограничения для разных роботов. Каждый блок ограничений должен начинаться со строки с полем User-Agent, указывающей робота, к которому относятся данные правила индексации сайта.
Часто встречающиеся ошибки
Нужно обязательно учитывать, что пустая строка в файле robots.txt представляет собой разделитель двух записей для разных роботов. Также нельзя указывать несколько директив в одной строке. Запрещая индексацию файла веб-мастера часто пропускают / перед названием файла.
Не нужно прописывать в robots.txt запрет на индексирование сайта для различных программ, которые предназначены для полного скачивания сайта, например, TeleportPro. Ни "программы-качалки", ни браузеры никогда не смотрят в этот файл и не выполняют прописанных там инструкций. Он предназначен исключительно для поисковых систем. Не стоит также блокировать в robots.txt админку вашего сайта, ведь если на нее нигде нет ссылки, то и индекироваться она не будет. Вы всего лишь раскроете расположение админки людям, которые не должны о ней знать. Также стоит помнить, что слишком большой robots.txt может быть проигнорирован поисковой системой. Если у вас слишком много страниц не предназначенных для индексации, то лучше их просто удалить с сайта или перенести в отдельную директорию и запретить индексирование данной директории.
Проверка файла robots.txt на наличие ошибок
Обязательно проверьте как понимает ваш файл robots поисковиковые системы. Для проверки Google вы можете воспользоваться Инструментами Google для веб-мастеров. Если вы хотите узнать как ваш файл robots.txt понимает Яндекс, то можете воспользоваться сервисом Яндекс.Вебмастер. Это позволит вовремя исправить допущенные ошибки. Также на страницах данных сервисов вы сможете найти рекомендации по составлению файла robots.txt и много другой полезной информации.
Копирование статьи запрещено.
В SEO мелочей не бывает. Иногда на продвижение сайта может оказать влияние всего лишь один небольшой файл — Robots.txt. Если вы хотите, чтобы ваш сайт зашел в индекс, чтобы поисковые роботы обошли нужные вам страницы, нужно прописать для них рекомендации.
«Разве это возможно?» , — спросите вы. Возможно. Для этого на вашем сайте должен быть файл robots.txt. Как правильно составить файл роботс , настроить и добавить на сайт – разбираемся в этой статье.
Что такое robots.txt и для чего нужен
Robots.txt – это обычный текстовый файл , который содержит в себе рекомендации для поисковых роботов: какие страницы нужно сканировать, а какие нет.
Важно: файл должен быть в кодировке UTF-8, иначе поисковые роботы могут его не воспринять.
Зайдет ли в индекс сайт, на котором не будет этого файла? Зайдет, но роботы могут «выхватить» те страницы, наличие которых в результатах поиска нежелательно: например, страницы входа, админпанель, личные страницы пользователей, сайты-зеркала и т.п. Все это считается «поисковым мусором»:
Если в результаты поиска попадёт личная информация, можете пострадать и вы, и сайт. Ещё один момент – без этого файла индексация сайта будет проходить дольше.
В файле Robots.txt можно задать три типа команд для поисковых пауков:
- сканирование запрещено;
- сканирование разрешено;
- сканирование разрешено частично.
Все это прописывается с помощью директив.
Как создать правильный файл Robots.txt для сайта
Файл Robots.txt можно создать просто в программе «Блокнот», которая по умолчанию есть на любом компьютере. Прописывание файла займет даже у новичка максимум полчаса времени (если знать команды).
Также можно использовать другие программы – Notepad, например. Есть и онлайн сервисы, которые могут сгенерировать файл автоматически. Например, такие как CY-PR.com или Mediasova .
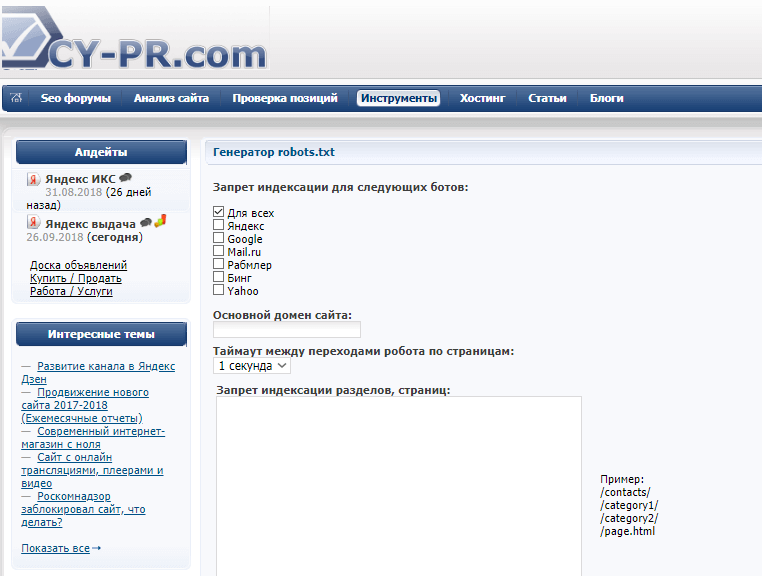
Вам просто нужно указать адрес своего сайта, для каких поисковых систем нужно задать правила, главное зеркало (с www или без). Дальше сервис всё сделает сам.
Лично я предпочитаю старый «дедовский» способ – прописать файл вручную в блокноте. Есть ещё и «ленивый способ» — озадачить этим своего разработчика 🙂 Но даже в таком случае вы должны проверить, правильно ли там всё прописано. Поэтому давайте разберемся, как составить этот самый файл, и где он должен находиться.
Готовый файл Robots.txt должен находиться в корневой папке сайта. Просто файл, без папки:

Хотите проверить, есть ли он на вашем сайте? Вбейте в адресную строку адрес: site.ru/robots.txt . Вам откроется вот такая страничка (если файл есть):

Файл состоит из нескольких блоков, отделённых отступом. В каждом блоке – рекомендации для поисковых роботов разных поисковых систем (плюс блок с общими правилами для всех), и отдельный блок со ссылками на карту сайта – Sitemap.
Внутри блока с правилами для одного поискового робота отступы делать не нужно.
Каждый блок начинается директивой User-agent.
После каждой директивы ставится знак «:» (двоеточие), пробел, после которого указывается значение (например, какую страницу закрыть от индексации).
Нужно указывать относительные адреса страниц, а не абсолютные. Относительные – это без «www.site.ru». Например, вам нужно запретить к индексации страницу www.site.ru/shop . Значит после двоеточия ставим пробел, слэш и «shop»:
Disallow: /shop.
Звездочка (*) обозначает любой набор символов.
Знак доллара ($) – конец строки.
Вы можете решить – зачем писать файл с нуля, если его можно открыть на любом сайте и просто скопировать себе?
Для каждого сайта нужно прописывать уникальные правила. Нужно учесть особенности CMS . Например, та же админпанель находится по адресу /wp-admin на движке WordPress, на другом адрес будет отличаться. То же самое с адресами отдельных страниц, с картой сайта и прочим.
Настройка файла Robots.txt: индексация, главное зеркало, диррективы
Как вы уже видели на скриншоте, первой идет директива User-agent. Она указывает, для какого поискового робота будут идти правила ниже.
User-agent: * — правила для всех поисковых роботов, то есть любой поисковой системы (Google, Yandex, Bing, Рамблер и т.п.).
User-agent: Googlebot – указывает на правила для поискового паука Google.
User-agent: Yandex – правила для поискового робота Яндекс.
Для какого поискового робота прописывать правила первым, нет никакой разницы. Но обычно сначала пишут рекомендации для всех роботов.
Disallow: Запрет на индексацию
Чтобы запретить индексацию сайта в целом или отдельных страниц, используется директива Disallow.
Например, вы можете полностью закрыть сайт от индексации (если ресурс находится на доработке, и вы не хотите, чтобы он попал в выдачу в таком состоянии). Для этого нужно прописать следующее:
User-agent: *
Disallow: /
Таким образом всем поисковым роботам запрещено индексировать контент на сайте.
А вот так можно открыть сайт для индексации:
User-agent: *
Disallow:
Потому проверьте, стоит ли слеш после директивы Disallow, если хотите закрыть сайт. Если хотите потом его открыть – не забудьте снять правило (а такое часто случается).
Чтобы закрыть от индексации отдельные страницы, нужно указать их адрес. Я уже писала, как это делается:
User-agent: *
Disallow: /wp-admin
Таким образом на сайте закрыли от сторонних взглядов админпанель.
Что нужно закрывать от индексации в обязательном порядке:
- административную панель;
- личные страницы пользователей;
- корзины;
- результаты поиска по сайту;
- страницы входа, регистрации, авторизации.
Можно закрыть от индексации и отдельные типы файлов. Допустим, у вас на сайте есть некоторые.pdf-файлы, индексация которых нежелательна. А поисковые роботы очень легко сканируют залитые на сайт файлы. Закрыть их от индексации можно следующим образом:
User-agent: *
Disallow: /*. pdf$
Как отрыть сайт для индексации
Даже при полностью закрытом от индексации сайте можно открыть роботам путь к определённым файлам или страницам. Допустим, вы переделываете сайт, но каталог с услугами остается нетронутым. Вы можете направить поисковых роботов туда, чтобы они продолжали индексировать раздел. Для этого используется директива Allow:
User-agent: *
Allow: /uslugi
Disallow: /
Главное зеркало сайта
До 20 марта 2018 года в файле robots.txt для поискового робота Яндекс нужно было указывать главное зеркало сайта через директиву Host. Сейчас этого делать не нужно – достаточно настроить постраничный 301-редирект .
Что такое главное зеркало? Это какой адрес вашего сайта является главным – с www или без. Если не настроить редирект, то оба сайта будут проиндексированы, то есть, будут дубли всех страниц.
Карта сайта: robots.txt sitemap
После того, как прописаны все директивы для роботов, необходимо указать путь к Sitemap. Карта сайта показывает роботам, что все URL, которые нужно проиндексировать, находятся по определённому адресу. Например:
Sitemap: site.ru/sitemap.xml
Когда робот будет обходить сайт, он будет видеть, какие изменения вносились в этот файл. В итоге новые страницы будут индексироваться быстрее.
Директива Clean-param
В 2009 году Яндекс ввел новую директиву – Clean-param. С ее помощью можно описать динамические параметры, которые не влияют на содержание страниц. Чаще всего данная директива используется на форумах. Тут возникает много мусора, например id сессии, параметры сортировки. Если прописать данную директиву, поисковый робот Яндекса не будет многократно загружать информацию, которая дублируется.
Прописать эту директиву можно в любом месте файла robots.txt.
Параметры, которые роботу не нужно учитывать, перечисляются в первой части значения через знак &:
Clean-param: sid&sort /forum/viewforum.php
Эта директива позволяет избежать дублей страниц с динамическими адресами (которые содержат знак вопроса).
Директива Crawl-delay
Эта директива придёт на помощь тем, у кого слабый сервер.
Приход поискового робота – это дополнительная нагрузка на сервер. Если у вас высокая посещаемость сайта, то ресурс может попросту не выдержать и «лечь». В итоге робот получит сообщение об ошибке 5хх. Если такая ситуация будет повторяться постоянно, сайт может быть признан поисковой системой нерабочим.
Представьте, что вы работаете, и параллельно вам приходится постоянно отвечать на звонки. Ваша продуктивность в таком случае падает.
Так же и с сервером.
Вернемся к директиве. Crawl-delay позволяет задать задержку сканирования страниц сайта с целью снизить нагрузку на сервер. Другими словами, вы задаете период, через который будут загружаться страницы сайта. Указывается данный параметр в секундах, целым числом:
ROBOTS.TXT - Стандарт исключений для роботов - файл в текстовом формате.txt для ограничения доступа роботам к содержимому сайта. Файл должен находиться в корне сайта (по адресу /robots.txt). Использование стандарта необязательно, но поисковые системы следуют правилам, содержащимся в robots.txt. Сам файл состоит из набора записей вида
:где поле - название правила (User-Agent, Disallow, Allow и проч.)
Записи разделяются одной или более пустых строк (признак конца строки: символы CR, CR+LF, LF)
Как правильно настроить ROBOTS.TXT?
В данном пункте приведены основные требования по настройке файла, конкретные рекомендации по настройке , примеры для популярных CMS
- Размер файла не должен превышать 32 кБ.
- Должна использоваться кодировка ASCII или UTF-8.
- В правильном файле robots.txt должны обязательно присутствовать хотя бы одно правило, состоящие из нескольких директив. Каждое правило обязательно должно содержать следующие директивы:
- для какого робота данное правило (директива User-agent)
- к каким ресурсам у данного агента есть доступ (директива Allow), либо к каким ресурсам нет доступа (Disallow).
- Каждое правило и директива должны начинаться с новой строки.
- Значение правила Disallow/Allow должно начинаться либо с символа /, либо с *.
- Все строки, начинающиеся с символа #, либо части строк начиная с данного символа считаются комментариями и не учитываются агентами.
Таким образом минимальное содержание правильно настроенного файла robots.txt выглядит так:
User-agent: * #для всех агентов Disallow: #запрещено ничего = разрешен доступ ко всем файлам
Как создать/изменить ROBOTS.TXT?
Создать файл возможно с помощью любого текстового редактора (например, notepad++). Для создание либо изменения файла robots.txt обычно требуется доступ к серверу по FTP/SSH, впрочем, многие CMS/CMF имеют встроенный интерфейс управления содержимым файла через панель администрирования (“админку”), например: Bitrix, ShopScript и другие.
Для чего нужен файл ROBOTS.TXT на сайте?
Как видно из определения, robots.txt позволяет управлять поведением роботов при посещении сайта, т.е. настроить индексирование сайта поисковыми системами - это делает данный файл важной частью SEO-оптимизации вашего сайта. Самая важная возможность robots.txt - запрет на индексацию страниц/файлов несодержащих полезную информацию. Либо вообще всего сайта, что может быть необходимо, например, для тестовых версий сайта.
Основные примеры того, что нужно закрывать от индексации будут рассмотрены ниже.
Что нужно закрывать от индексации?
Во-первых, всегда следует запрещать индексация сайтов в процессе разработки, чтобы избежать попадания в индекс страниц, которых вообще не будет на готовой версии сайта и страниц с отсутствующим/дублированным/тестовым контентом до того как они будут заполнены.
Во-вторых, следует скрыть от индексации копии сайта, созданные как тестовые площадки для разработки.
В-третьих, разберем какой контент непосредственно на сайте нужно запрещать индексировать.
- Административная часть сайта, служебные файлы.
- Страницы авторизации/регистрации пользователя, в большинстве случаев - персональные разделы пользователей (если не предусмотрен публичный доступ к личным страницам).
- Корзина и страницы оформления, просмотра заказа.
- Страницы сравнения товаров, возможно выборочно открывать такие страницы для индексации при условии их уникальности. В общем случае таблицы сравнения - бессчетное количество страниц с дублированным контентом.
- Страницы поиска и фильтрации возможно оставлять открытыми для индексации только в случае их правильной настройки: отдельные урлы, заполненные уникальные заголовки, мета-теги. В большинстве случаев такие страницы следует закрывать.
- Страницы с сортировками товаров/записей, в случае наличия у них разных адресов.
- Страницы с utm-, openstat-метками в URl (а также всеми прочими).
Синтаксис ROBOTS.TXT
Теперь остановимся на синтаксисе robots.txt более подробно.
Общие положения:
- каждая директива должна начинаться с новой строки;
- строка не должна начинаться с пробела;
- значение директивы должно быть в одну строку;
- не нужно обрамлять значения директив в кавычки;
- по умолчанию для всех значений директив в конце прописывается *, Пример: User-agent: Yandex Disallow: /cgi-bin* # блокирует доступ к страницам Disallow: /cgi-bin # то же самое
- пустой перевод строки трактуется как окончание правила User-agent;
- в директивах «Allow», «Disallow» указывается только одно значение;
- название файла robots.txt не допускает наличие прописных букв;
- robots.txt размером более 32 Кб не допускается, роботы не будут загружать такой файл и посчитают сайт полностью разрешенным;
- недоступный robots.txt может трактовуется как полностью разрешающий;
- пустой robots.txt считается полностью разрешающим;
- для указания кириллических значений правил используйте Punycod;
- допускаются только кодировки UTF-8 и ASCII: использование любых национальных алфавитов и прочих символов в robots.txt не допускается.
Специальные символы:
- #
Символ начала комментирования, весь текст после # и до перевода строки считается комментарием и не используется роботами.
*Подстановочное значение обозначающее префикс, суффикс либо значение директивы полностью - любой набор символов (в том числе пустой).
- $
Указание на конец строки, запрет достраивания * к значению, наПример:
User-agent: * #для всех Allow: /$ #разрешить индексацию главной страницы Disallow: * #запретить индексацию всех страниц, кроме разрешенной
Список директив
- User-agent
Обязательная директива. Определяет к какому роботу относится правило, в правиле может быть одна или несколько таких директив. Можно использовать символ * как указание префикса, суффикса или полного названия робота. Пример:
#сайт закрыт для Google.Новости и Google.Картинки User-agent: Googlebot-Image User-agent: Googlebot-News Disallow: / #для всех роботов, чье название начинается с Yandex, закрываем раздел “Новости” User-agent: Yandex* Disallow: /news #открыт для всех остальных User-agent: * Disallow:
- Disallow
Директива указывает какие файлы или каталоги нельзя индексировать. Значение директивы должно начинаться с символа / либо *. По умолчанию в конце значения проставляется *, если это не запрещено символом $.
- Allow
В каждом правиле должна быть по крайней мере одна директива Disallow: или Allow:.
Директива указывает какие файлы или каталоги следует индексировать. Значение директивы должно начинаться с символа / либо *. По умолчанию в конце значения проставляется *, если это не запрещено символом $.
Использование директивы актуально только совместно с Disallow для разрешения индексации какого-то подмножества запрещенных к индексированию страниц директивой Disallow.
- Clean-param
Необязательная, межсекционная директива. Используйте директиву Clean-param, если адреса страниц сайта содержат GET-параметры (в URL отображается после знака?), которые не влияют на их содержимое (например, UTM). С помощью данного правила все адреса будут приведены к единому виду - исходному, без параметров.
Синтаксис директивы:
Clean-param: p0[&p1&p2&..&pn]
p0… - названия параметров, которые не нужно учитывать
path - префикс пути страниц, для которых применяется правилоПример.
на сайте есть страницы вида
Www.example.com/some_dir/get_book.pl?ref=site_1&book_id=123 www.example.com/some_dir/get_book.pl?ref=site_2&book_id=123 www.example.com/some_dir/get_book.pl?ref=site_3&book_id=123
При указании правила
User-agent: Yandex Disallow: Clean-param: ref /some_dir/get_book.pl
робот сведет все адреса страницы к одному:
Www.example.com/some_dir/get_book.pl?book_id=123
- Sitemap
Необязательная директива, возможно размещение нескольких таких директив в одном файле, межсекционная (достаточно указать в файле один раз, не дублируя для каждого агента).
Пример:
Sitemap: https://example.com/sitemap.xml
- Crawl-delay
Директива позволяет задать поисковому роботу минимальный период времени (в секундах) между окончанием загрузки одной страницы и началом загрузки следующей. Поддерживаются дробные значения
Минимально допустимое значение для роботов Яндекс - 2.0.
Роботы Google не учитывают данную директиву.
Пример:
User-agent: Yandex Crawl-delay: 2.0 # задает тайм-аут в 2 секунды User-agent: * Crawl-delay: 1.5 # задает тайм-аут в 1.5 секунды
- Host
Директива указывает главное зеркало сайта. На данный момент из популярных поисковых систем поддерживается только Mail.ru.
Пример:
User-agent: Mail.Ru Host: www.site.ru # главное зеркало с www
Примеры robots.txt для популярных CMS
ROBOTS.TXT для 1С:Битрикс
В CMS Битрикс предусмотрена возможность управления содержимым файла robots.txt. Для этого в административном интерфейсе нужно зайти в инструмент “Настройка robots.txt”, воспользовавшись поиском, либо по пути Маркетинг->Поисковая оптимизация->Настройка robots.txt. Также можно изменить содержимое robots.txt через встроенный редактор файлов Битрикс, либо через FTP.
Приведенный ниже пример может использоваться как стартовый набор robots.txt для сайтов на Битрикс, но не является универсальным и требует адаптации в зависимости сайта.
Пояснения:
- разбиение на правила для разных агентов обусловлено тем, что Google не поддерживает директиву Clean-param.
ROBOTS.TXT для WordPress
В “админке” Вордпресс нет встроенного инструмента для настройки robots.txt, поэтому доступ к файлу возможен только с помощью FTP, либо после установки специального плагина (например, DL Robots.txt).
Приведенный ниже пример может использоваться как стартовый набор robots.txt для сайтов на Wordpress, но не является универсальным и требует адаптации в зависимости сайта.
Пояснения:
- в директивах Allow указаны пути к файлам стилей, скриптов, картинок: для правильной индексации сайта необходимо, чтобы они были доступны роботам;
- для большинства сайтов страницы архивов записей по автору и меток только создают дублирование контента и не создают полезного контента, поэтому в данном примере они закрыты для индексации. Если же на вашем проекте подобные страницы необходимы, полезны и уникальны, то следует удалить директивы Disallow: /tag/ и Disallow: /author/.
Пример правильного ROBOTS.TXT для сайта на WoRdPress:
User-agent: Yandex # Для Яндекса Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: /xmlrpc.php Disallow: /tag/ Disallow: /readme.html Disallow: *?replytocom Allow: */uploads Allow: /*/*.js Allow: /*/*.css Allow: /wp-*.png Allow: /wp-*.jpg Allow: /wp-*.jpeg Allow: /wp-*.gif Clean-Param: utm_source&utm_medium&utm_campaign Clean-Param: openstat User-agent: * Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: /xmlrpc.php Disallow: *?utm Disallow: *openstat= Disallow: /tag/ Disallow: /readme.html Disallow: *?replytocom Allow: */uploads Allow: /*/*.js Allow: /*/*.css Allow: /wp-*.png Allow: /wp-*.jpg Allow: /wp-*.jpeg Allow: /wp-*.gif Sitemap: http://site.com/sitemap.xml #заменить на адрес вашей карты сайта
ROBOTS.TXT для OpenCart
В “админке” OpenCart нет встроенного инструмента для настройки robots.txt, поэтому доступ к файлу возможен только с помощью FTP.
Приведенный ниже пример может использоваться как стартовый набор robots.txt для сайтов на OpenCart, но не является универсальным и требует адаптации в зависимости сайта.
Пояснения:
- в директивах Allow указаны пути к файлам стилей, скриптов, картинок: для правильной индексации сайта необходимо, чтобы они были доступны роботам;
- разбиение на правила для разных агентов обусловлено тем, что Google не поддерживает директиву Clean-param;
ROBOTS.TXT для Joomla!
В “админке” Джумла нет встроенного инструмента для настройки robots.txt, поэтому доступ к файлу возможен только с помощью FTP.
Приведенный ниже пример может использоваться как стартовый набор robots.txt для сайтов на Joomla с включенным SEF, но не является универсальным и требует адаптации в зависимости сайта.
Пояснения:
- в директивах Allow указаны пути к файлам стилей, скриптов, картинок: для правильной индексации сайта необходимо, чтобы они были доступны роботам;
- разбиение на правила для разных агентов обусловлено тем, что Google не поддерживает директиву Clean-param;
Перечень основных агентов
| Бот | Функция |
| Googlebot | основной индексирующий робот Google |
| Googlebot-News | Google Новости |
| Googlebot-Image | Google Картинки |
| Googlebot-Video | видео |
| Mediapartners-Google | |
| Mediapartners | Google AdSense, Google Mobile AdSense |
| AdsBot-Google | проверка качества целевой страницы |
| AdsBot-Google-Mobile-Apps | Робот Google для приложений |
| YandexBot | основной индексирующий робот Яндекса |
| YandexImages | Яндекс.Картинки |
| YandexVideo | Яндекс.Видео |
| YandexMedia | мультимедийные данные |
| YandexBlogs | робот поиска по блогам |
| YandexAddurl | робот, обращающийся к странице при добавлении ее через форму «Добавить URL» |
| YandexFavicons | робот, индексирующий пиктограммы сайтов (favicons) |
| YandexDirect | Яндекс.Директ |
| YandexMetrika | Яндекс.Метрика |
| YandexCatalog | Яндекс.Каталог |
| YandexNews | Яндекс.Новости |
| YandexImageResizer | робот мобильных сервисов |
| Bingbot | основной индексирующий робот Bing |
| Slurp | основной индексирующий робот Yahoo! |
| Mail.Ru | основной индексирующий робот Mail.Ru |
Частые вопросы
Текстовый файл robots.txt является общедоступным, что следует учитывать, и не использовать данный файл как средство сокрытия конфиденциальной информации.
Есть ли отличия robots.txt для Яндекс и Google?
Принципиальных отличий в обработке robots.txt поисковыми системами Яндекс и Гугл нет, но все же следует выделить ряд моментов:
- как уже указывалось ранее правила в robots.txt носят рекомендательный характер, чем активно пользуется Google.
В документации по работе с robots.txt Google указывает , что “..не предназначена для того, чтобы запрещать показ веб-страниц в результатах поиска Google. “ и “Если файл robots.txt запрещает роботу Googlebot обрабатывать веб-страницу, она все равно может демонстрироваться в Google”. Для исключения страниц из поиска Google необходимо использовать мета-теги robots.
Яндекс же исключает из поиска страницы, руководствуясь правилами robots.txt.
- Яндекс в отличие от Google поддерживает директивы Clean-param и Crawl-delay.
- Роботы AdsBot Google не следует правилам для User-agent: *, для них необходимо задавать отдельные правила.
- Многие источники указывают, что файлы скриптов и стилей (.js, .css) нужно открывать для индексации только роботам Google. На самом деле это не соответствует действительности и следует открывать эти файлы и для Яндекс: с 9.11.2015 Яндекс начал использовать js и css при индексации сайтов (сообщение в официальном блоге).
Как закрыть сайт от индексации в robots.txt?
Чтобы закрыть сайт в Robots.txt нужно использовать одно из следующих правил:
User-agent: * Disallow: / User-agent: * Disallow: *
Возможно закрыть сайт только для какой-то одной поисковой системы (или нескольких), при этом оставив остальным возможность индексирования. Для этого в правиле нужно изменить директиву User-agent: заменить * на название агента, которому нужно закрыть доступ ().
Как открыть сайт для индексации в robots.txt?
В обычном случае, чтобы открыть сайт для индексации в robots.txt не нужно предпринимать никаких действий, просто нужно убедиться, что в robots.txt открыты все необходимые директории. Например, если ранее ваш сайт был скрыт от индексации, то следует удалить из robots.txt следующие правила (в зависимости от использованного):
- Disallow: /
- Disallow: *
Обратите внимание, что индексация может быть запрещена не только с помощью файла robots.txt, но и использованием мета-тега robots.
Также следует учесть, что отсутствие файла robots.txt в корне сайта означает, что индексация сайта разрешена.
Как указать главное зеркало сайта в robots.txt?
На данный момент указание главного зеркала с помощью robots.txt невозможно. Ранее ПС Яндекс использовала директиву Host, которая и содержало указание на основное зеркало, но с 20 марта 2018 Яндекс полностью отказался от ее использования. Сейчас указание главного зеркала возможно только с помощью 301-го постраничного редиректа.